2026 OPENROUTER
TOKEN_
VS_
REVENUE_
MAC.
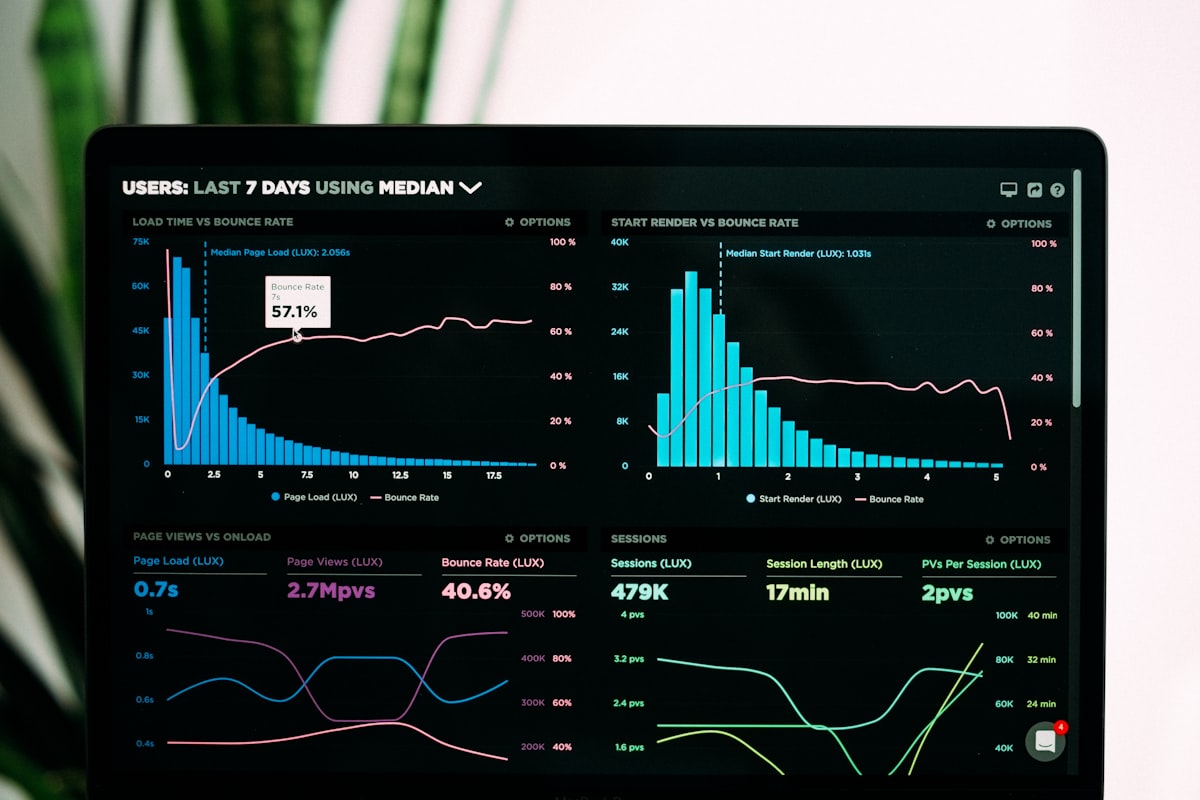
Open openrouter.ai/rankings and you get Top Models, Market Share, Trending, and more — but your invoice and "what is hot" rarely line up. The May series already decoded the overall chart, Programming, Tool Calls, multimodal input, and Image Output / Languages slices. Early June requires a dedicated "dual-track read": picking default models by weekly token volume vs controlling budget by USD revenue / unit price are two different control loops. Third-party snapshots of OpenRouter public endpoints (2026-05-30) show roughly 31.34T tokens/week platform-wide and an estimated $32.4M weekly revenue; Anthropic captures ~42% of revenue on only ~11% of token share, while Xiaomi MiMo-V2.5-Pro hit ~2.30T weekly tokens (+432% WoW) at ~$438K revenue. This article delivers: early-June snapshot — dual-track comparison — Provider layer — WoW anomalies — six rollout steps — decision matrix — case study — acceptance checklist.
1. Pain points: follow the wrong chart = cost blowout or capability mismatch
(1) Treating Top Models as "best overall": leaders are mostly MiMo-V2.5, DeepSeek V4, Qwen — low-cost, high-throughput models suited for Agent token flooding, not necessarily optimal for hard reasoning. (2) Ignoring the revenue chart: Claude Opus 4.7 may consume modest token share on some Provider routes but eats budget at $5/$25 per M pricing tiers. (3) Conflating model author with routing provider: SiliconFlow moves ~4.04T tokens/week (second only to Google at 4.28T), yet Market Share may display DeepSeek/Qwen as the base model author — ops changes the Provider, not the author string. (4) No cap on WoW surges: Xiaomi token +432%, Alibaba +75% in one week; if Cursor/OpenClaw default models are hard-coded, fallback may silently switch to an untested path. (5) Local Mac vs API not split: DeepSeek/Qwen workloads that could run on MLX still hit OpenRouter — unified memory idle while API bills climb.
2. Three sentences to read OpenRouter platform-wide (early June)
| Dimension | Early-June snapshot (public aggregate) | Mac read |
|---|---|---|
| Platform throughput | ~31.34T tokens/week; ~$32.4M weekly revenue (est.) | Agent scale is baseline; budget must be bucketed |
| Token volume #1 provider | Google ~4.28T; SiliconFlow ~4.04T | Track Provider stability, not just model name |
| Token volume surges | Xiaomi +432% WoW; Stealth/Owl ~1.58T emerging | Weekly diff on defaults and fallback chains |
| Revenue #1 | Anthropic ~42% (~$13.6M/week) | Hard-task fallback, not daily default |
| Chinese-vendor tokens | Combined still >60% (multiple analyses agree) | Cost-friendly; compliance evaluated separately |
3. Dual-track comparison: volume kings vs revenue kings (why they are not the same models)
| Track | Representatives | Weekly tokens (approx.) | Weekly revenue (approx.) | Typical Mac use |
|---|---|---|---|---|
| Volume king | MiMo-V2.5-Pro, DeepSeek V4 Pro, Qwen 3.6+ | Xiaomi 2.30T; DeepSeek 1.32T | Xiaomi ~$438K; DeepSeek ~$219K | Cursor completion, OpenClaw daily Agent |
| Revenue king | Claude Opus 4.7, GPT-5.5 | Anthropic 3.51T (family total) | Anthropic ~$13.6M (42%) | Architecture review, hard bugs, compliance fallback |
| Misalignment example | Google routing + Claude billing | Google highest token volume | Bedrock/Azure stacks Anthropic pricing | Verify actual Provider in IDE config |
Conclusion: follow Top Models / Market Share to pick "default cheap models"; follow revenue structure to cap "expensive model quota." Both hold simultaneously — the platform stratifies between commodity token and premium dollar layers. Mac teams should maintain two routing tables, not one.
4. Provider layer: SiliconFlow, Novita, and author charts are not the same thing
OpenRouter Market Share slices by model author (Xiaomi, Qwen, Anthropic); actual requests also traverse Providers (SiliconFlow, Novita, DeepInfra, official direct, etc.). In the 5/30 snapshot, SiliconFlow ~4.04T tokens but only ~$609K revenue indicates massive traffic on ultra-low marginal-price routes; Novita ~1.77T with -19% WoW shows Providers reshuffle violently too. When configuring OpenRouter on Mac, beyond the model field, log the actual hit provider (OpenRouter Usage panel) to avoid "same model name, different latency/rate limits."
5. WoW alert: how to write fallback for surging models
In one week: Xiaomi token +1.87T (+432%), Alibaba +612B (+75%); StepFun, Novita, Moonshot dropped significantly. OpenClaw / Cursor should use a three-tier fallback: (1) default: MiMo-V2.5 or DeepSeek V4 Flash (volume chart + low price); (2) quality: Qwen3.7 / GLM-5; (3) fallback: Claude Opus 4.7 (daily token cap). During surge weeks, do not auto-upgrade default models without limits — run 50 regression prompts on a remote Mac or locally before switching production.
6. Six steps: dual-track charts to Mac routing table
Step 1 — Open rankings + Usage weekly
Record Top Models top five vs your bill's top three models; mismatch means you are already on the wrong track.
Step 2 — Build Token track and Dollar track tables
Token track: defaults and Agents. Dollar track: Opus/GPT daily caps (e.g. $20/day).
Step 3 — Annotate Provider
For DeepSeek V4 Pro etc., log SiliconFlow vs official P95 latency.
Step 4 — Local MLX baseline
Quantized Qwen/DeepSeek sizes that fit Apple Silicon: daytime local /v1, nightly Agent via OpenRouter.
Step 5 — Align OpenClaw openclaw.json
Primary model and fallback arrays split by track; see fallback drift runbook.
Step 6 — On 429/rate limit: downgrade track before upgrade
Switch Token-track alternates first, then escalate Dollar track; avoid jumping straight to Opus for everything.
7. Three-lane decision matrix: local MLX / OpenRouter API / remote Mac
| Scenario | Path | Which chart | Acceptance |
|---|---|---|---|
| IDE daily completion | Local Ollama/MLX or OpenRouter low-cost tier | Token track Top5 | P95 <800ms; equivalent <$0.3/M |
| OpenClaw 7×24 Agent | Remote Mac Gateway + OpenRouter | Token track + Provider stability | 24h no disconnect; predictable daily tokens |
| Architecture / security review | OpenRouter Opus 4.7 | Dollar track | Daily cap; auto-downgrade after task |
| Heavy coding tasks | DeepSeek V4 Flash + Opus fallback | Programming slice + Dollar track | See 0526 Programming chart article |
| Local 32GB saturated | Remote Mac 128GB MLX baseline | A/B vs API | TTFT and $/1M on same sheet |
8. Case study: 10-person Mac team dual-track reroute, OpenRouter monthly spend down 38%
"Ten full-stack engineers on MacBook Pro M3 Max 36GB + Studio M2 Ultra: Cursor default Claude Opus 4.7 (following 'capability intuition'), OpenClaw on MiMo, $6,800/mo OpenRouter. Early June dual-track reroute: 80% of interactions moved to MiMo-V2.5 + DeepSeek V4 Flash (Token track); Opus only for PR security review (Dollar track cap $15/person/day); DeepSeek A/B SiliconFlow vs official, P95 similar so pick lower price; Studio runs MLX Qwen 32B nights absorbing 40% of completions. After 30 days: $4,220, -38%; Opus call count -71%, hard-task satisfaction unchanged."
Takeaway: the bill spike came from Dollar track misconfigured as default, not "OpenRouter is too expensive." Chinese open models on Top Models are built for volume; Opus should be the ER, not the primary care clinic.
9. Industry insight: dual-track structure is here to stay
At 31T tokens/week, the inference market has split into a commodity token layer (Chinese open models + Provider bidding) and a premium dollar layer (Anthropic/Google/OpenAI high-price tiers). Stealth models (e.g. Owl Alpha) breaking 1.5T weekly tokens show "off-chart" traffic matters too. Mac ecosystem advantage: the same machine can run MLX to validate Token-track models, then A/B against OpenRouter; Windows/Linux cloud hosts can run Agents, but lag on Xcode/Cursor local debug, ColorSync asset chains, launchd persistent Gateway. When local Agent + IDE both contend for 36GB unified memory, the cleanest split is a remote Apple Silicon Mac running OpenClaw 24/7 while the laptop keeps Cursor and Dollar-track fallback only.
Pure Windows or cloud GPU can drive OpenRouter API, but when 7×24 Gateway, Metal sidecar inference, and graphics workflows coexist, maintenance cost often exceeds macOS. If you want Agents stable on Token track while the laptop handles review and expensive-model fallback, consider MACGPU remote Mac nodes preloaded with OpenClaw + routing table templates, aligned to your dual-track acceptance gates.
10. Citable numbers and FAQ
① Platform weekly tokens (5/30 aggregate): ~31.34T. ② Weekly revenue estimate: ~$32.4M. ③ Anthropic revenue share: ~42%; token share ~11%. ④ Xiaomi weekly tokens: ~2.30T (+432% WoW). ⑤ SiliconFlow weekly tokens: ~4.04T. ⑥ Case monthly spend: $6,800 → $4,220 (-38%).
Q: Still read May sub-charts? A: Yes — Programming/Tool/multimodal/Image Output still apply; this article adds dual-track + Provider layer. Q: Can MiMo replace Opus globally? A: No; split by track. Q: What does MACGPU solve? A: Remote Mac absorbs Token-track Agent peaks; laptop keeps Dollar track and MLX baseline.