2026 OPENROUTER
LES DONNÉES_
DE FACTURATION_
NE MENTENT PAS.
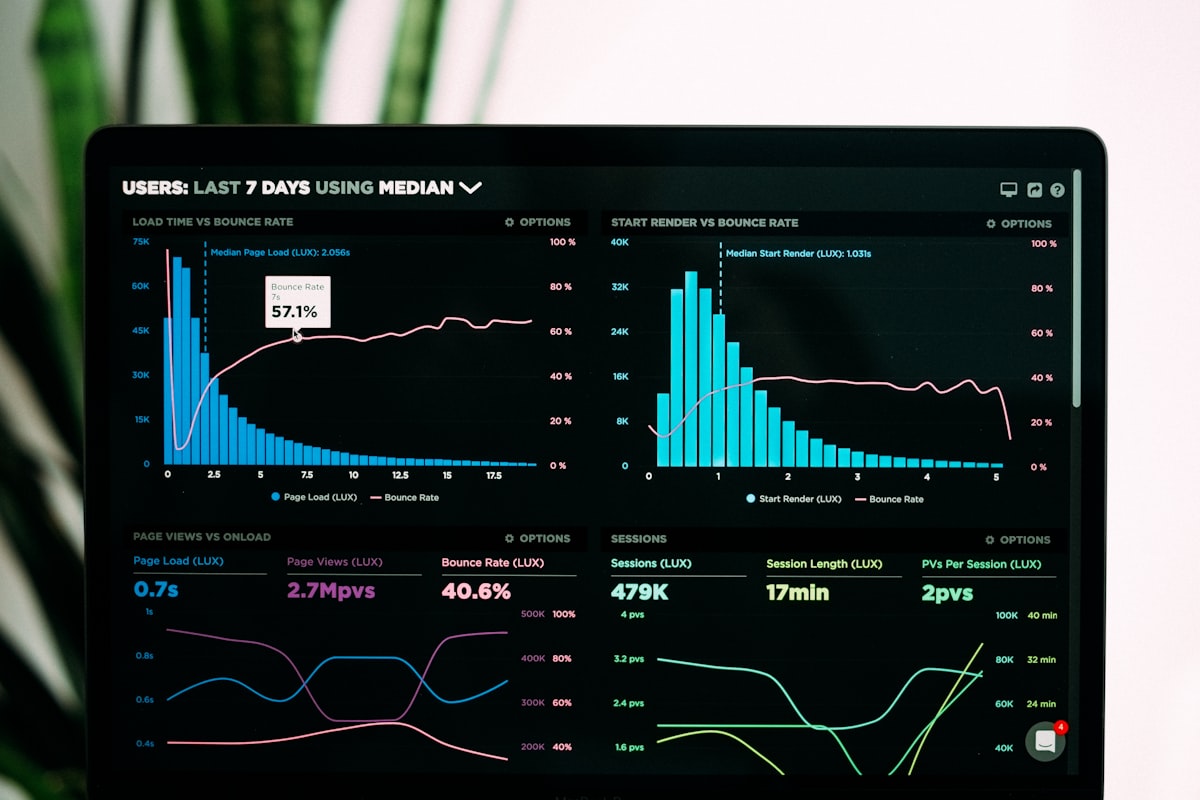
Les sommets MMLU tournent au rythme des keynotes, mais les 28,9 billions de tokens réellement facturés sur OpenRouter la semaine du 18 au 24 mai 2026 constituent une vérité comptable : DeepSeek-V4-Flash mène avec 3,43 T, les modèles chinois totalisent 9,22 T et dépassent les États-Unis pour la quatrième semaine consécutive. Problème : les équipes créatives et techniques se laissent guider par les benchmarks éditeurs, alors que la facture vote pour les modèles à haut débit et bas coût. Conclusion : le volume de tokens est le thermomètre de la commercialisation de l'IA ; Anthropic ne capte que 12 % du trafic mais environ 46 % des revenus en dollars — preuve d'une inversion « classement labo vs classement marché ». Plan : sources → volume global → Top 10 → double lecture fournisseurs → découverte a16z → cinq étapes Mac → étude de cas studio → conversion.
1. Anatomie du problème : pourquoi la facturation prime sur le benchmark
1) Les benchmarks se optimisent, le trafic réel se paie : un leaderboard peut être ciblé sur un jeu d'évaluation ; des billions de tokens routés chaque semaine représentent des charges de production — prix, latence, fiabilité des appels d'outils. 2) « Le plus fort » n'est pas « le plus utilisé » : Claude Opus reste une référence pour le raisonnement complexe, mais son volume hebdomadaire peut être dix fois inférieur à DeepSeek Flash ; l'entreprise paie la qualité, la masse paie le débit. 3) Le rapport Chine / États-Unis s'est inversé : début 2025, les modèles chinois représentaient moins de 2 % du trafic OpenRouter ; en mai 2026, ils dépassent 45 %. Un routage figé sur GPT/Claude par défaut est déjà obsolète. 4) Le code domine l'usage : le rapport conjoint OpenRouter × a16z montre la part « programmation » passer de 11 % début 2025 à plus de 50 % — il faut des chaînes par scénario, pas un modèle unique. 5) Workflows créatifs exigeants : montage Final Cut, pipelines ComfyUI et agents Cursor/OpenClaw en parallèle imposent une répartition mémoire unifiée rigoureuse sur Mac — le mauvais routage API aggrave la pression RAM autant qu'un mauvais choix de modèle.
Pour les directeurs techniques de studios et agences, ignorer le classement hebdomadaire équivaut à piloter un budget cloud sans relevé bancaire. La croissance continue (+7,4 % WoW, cinquième semaine) et l'accélération chinoise (+19,89 %) obligent à une revue hebdomadaire — pas une mise à jour trimestrielle dans un slide deck.
Les modèles gratuits ou en preview (Owl Alpha, Hy3) génèrent des pics de charge sans revenu direct, mais signalent les routes standard de demain. Les ignorer, c'est payer deux fois pendant la migration : ancien défaut plus nouvelle chaîne de secours. Pour les productions créatives, chaque entrée du Top 10 mérite une lecture « coût par minute de montage assisté » et non seulement « score MMLU » — la facturation reflète le tempo réel des équipes.
2. Sources et méthodologie statistique
Les données proviennent du classement public openrouter.ai/rankings, mesurant le débit de tokens sur 7 jours glissants (entrée + sortie). OpenRouter agrège 300+ modèles de 60+ fournisseurs, traite environ 100 billions de tokens par mois pour plus de 8 millions d'utilisateurs — le snapshot hebdomadaire offre une vue multi-fournisseurs, multi-régions et multi-scénarios. Période principale : 18–24 mai 2026 ; début juin, le volume hebdomadaire plateforme dépasse 33 T+ (suivi tiers), tendance alignée sur fin mai. Recoupements : NBD 25.05.2026, rapport OpenRouter × a16z « 2025 AI Usage Report », analyse Digital Applied juin.
Limite méthodologique : OpenRouter mesure le routage API, pas l'inférence MLX locale. Les équipes Mac avec modèles 7B–32B quantifiés en local n'apparaissent pas dans ce classement — d'où notre protocole d'acceptation interne (50 prompts, étape 5). Pour les productions audiovisuelles, documenter quels tracks API touchent des données client (voie dollar) vs batches anonymisés (voie tokens).
3. Volume hebdomadaire mondial : 28,9 billions de tokens, cinquième hausse consécutive
| Indicateur | Valeur | WoW | Lecture |
|---|---|---|---|
| Volume hebdomadaire global | 28,9 billions de tokens | +7,4 % | Cinquième semaine de croissance — inférence à l'échelle |
| Modèles chinois | 9,223 billions | +19,89 % | Croissance supérieure à la moyenne mondiale |
| Modèles américains | 4,93 billions | +16,27 % | Croissance réelle, part relative en baisse |
| Chine vs États-Unis | Chine > USA | 4 semaines | Modèles chinois en tête du volume hebdo |
| Comparaison annuelle | ~2,4 T → 28,9 T | ~12× | Il y a un an, le volume hebdo était un ordre de grandeur inférieur |
Échelle : 28,9 billions de tokens dépassent le trafic cumulé de toutes les démos keynote d'un trimestre — indicateur de déploiement commercial, pas de score de laboratoire. Pour un producteur de contenu IA : à ~0,14 $/M en sortie (ordre de grandeur V4-Flash) contre ~25 $/M (classe Opus), une erreur de routage multiplie la ligne OpenRouter par 180 sans gain perceptible sur les tâches de code standard.
L'accélération chinoise s'explique par la matrice DeepSeek à prix agressif, la rétention post-preview de Tencent Hy3, et l'adoption massive des agents (OpenClaw, Cursor) sur le tier Flash. La croissance américaine repose sur Gemini Flash et Claude Sonnet — qualité élevée, volume inférieur à l'ensemble chinois.
4. Top 10 des modèles de la semaine (18–24 mai 2026)
| Rang | Modèle | Éditeur | Tokens/semaine | WoW | Profil |
|---|---|---|---|---|---|
| 1 | DeepSeek-V4-Flash | DeepSeek (Chine) | 3,43 T | +66 % | Agents, prix minimal |
| 2 | Tencent Hy3 Preview | Tencent (Chine) | 3,07 T | +16 % | Forte rétention post-preview |
| 3 | Claude Sonnet 4.6 | Anthropic (USA) | 1,35 T | — | 1M contexte, code entreprise |
| 4 | DeepSeek-V3.2 | DeepSeek (Chine) | 1,31 T | — | Long tail économique |
| 5 | Owl Alpha | OpenRouter | 1,15 T | +29 % | Agent gratuit, 1M contexte |
| 6 | Gemini 3 Flash Preview | Google (USA) | 1,06 T | — | Multimodal, académique |
| 7 | DeepSeek-V4-Pro | DeepSeek (Chine) | 1,00 T | — | Flagship (série ~5,74 T) |
| 8 | MiniMax M2.7 | MiniMax (Chine) | 806 B | — | Long contexte, rapport qualité/prix |
| 9 | Grok 4.1 Fast | xAI (USA) | 721 B | — | 2M contexte, juridique |
| 10 | Step 3.5 Flash | StepFun (Chine) | 673 B | — | Rapide, batch |
La matrice DeepSeek domine : V4-Flash, V4-Pro et V3.2 simultanément dans le Top 10 ; total série 5,74 billions (+25,9 % WoW), deux semaines consécutives en tête fournisseur devant Anthropic et Google. Kimi K2.6 est sorti du Top 10 — le classement hebdo est volatile ; un routage figé mensuellement est risqué. Owl Alpha (+29 %) signale la demande d'agents gratuits ; à réserver aux prompts non sensibles.
Lecture professionnelle : six places sur dix sont chinoises ; la représentation américaine se concentre sur Sonnet, Gemini et Grok — segments à ARPU moyen à élevé. Ce Top 10 est un classement économique sous charge réelle, pas un palmarès de qualité absolue.
5. Paysage fournisseurs : voie tokens vs voie dollars
| Segment | Représentants | Profil tokens | Profil revenus | Scénarios typiques |
|---|---|---|---|---|
| Haute valeur · faible volume | Claude Opus 4.6/4.7 | ~12 %, en recul | ~46 % part USD | Raisonnement entreprise, conformité |
| Rapport qualité/prix · volume moyen | Gemini 3 Flash | croissance stable | ARPU moyen | Multimodal, documentation |
| Ultra-bas coût · fort volume | DeepSeek / Hy3 / MiniMax | 45 %+ plateforme | revenus << part tokens | Agents, code, batch |
Paradoxe Anthropic : les entreprises paient encore Opus (presse ~25 M$/mois), mais l'hégémonie du trafic appartient aux matrices chinoises bon marché. Le marché se scinde en voie tokens (volume, débit) et voie dollars (audit, architecture). Les studios Mac doivent configurer les deux — voir le guide double classement. Voie dollar pour données client et revue créative sensible ; voie tokens pour agents et batches anonymisés.
Les investisseurs interprètent cette scission comme signal de valorisation (OpenRouter ~26× PS rapporté) ; les équipes créatives doivent appliquer la même logique au budget mensuel — routage conscient de l'ARPU, pas modèle unique par défaut.
6. Découverte contre-intuitive : l'inversion a16z entre score et part de marché
Le rapport OpenRouter × a16z couvre ~100 billions de métadonnées anonymes : les scores de benchmark et la part de marché sont quasi inversément corrélés. Les équipes optimisent coût d'inférence, latence P95 et stabilité des tool calls — pas un point SOTA isolé. Les pipelines d'agents exigent un débit prévisible ; un leader SWE-bench à 25 $/M sortie cède face à V4-Flash (~0,14 $/M) dans un IDE à plus d'un million de tokens par jour. La part code >50 % amplifie l'effet.
Pour les workflows créatifs professionnels : les revues d'architecture et de conformité restent sur la voie dollar (Opus/Sonnet), mais 60–70 % du budget tokens relève logiquement du tier Flash — sinon la ligne OpenRouter explose sans gain qualitatif sur le code standard ou la génération de scripts batch. La facture est plus honnête que tout palmarès.
7. Cinq étapes : intégrer le classement hebdo dans le workflow Mac
Étape 1 — Chaque lundi, consulter rankings et archiver le diff Top 10
Noter les changements de rang et les modèles WoW >30 % ; marquer les nouveaux entrants (Owl Alpha) en pool gris. Archiver dans Git pour traçabilité production.
Étape 2 — Scinder les chaînes par tâche, pas de défaut global
Agent/batch → DeepSeek-V4-Flash ; raisonnement complexe → Claude Opus ; multimodal → Gemini 3 Flash. Profils openclaw.json distincts pour Cursor et OpenClaw Gateway.
Étape 3 — Étiqueter les trois voies Mac : MLX local / API OpenRouter / Mac distant
7B–32B quantifié en steady-state → MLX local sur Apple Silicon ; contexte 1M et modèles preview → API ; Gateway OpenClaw 7×24 → nœud Mac distant en launchd, libérant la mémoire unifiée pour Final Cut et ComfyUI sur le portable 16 Go.
Étape 4 — Plafond budgétaire mensuel sur la voie dollars
Opus/GPT réservés à l'architecture et la sécurité ; au-delà de +15 % du budget mensuel, bascule automatique vers V4-Flash ou Hy3.
Étape 5 — Acceptation hebdomadaire sur 50 prompts
Même jeu de prompts sur MLX local, API OpenRouter et Mac distant ; comparer latence P50/P95, $/M tokens et taux de succès des tool calls.
8. Étude de cas : un studio de six personnes réduit la facture de 39 %
« Point de départ : Claude Sonnet par défaut pour tous les scénarios, OpenRouter ~3 200 $/mois. Après alignement sur le classement 18–24 mai : 62 % des tokens vers DeepSeek-V4-Flash (agents + Cursor), 18 % Hy3 preview en gris, 12 % Gemini 3 Flash multimodal, 8 % Opus réservé à l'audit sécurité. Quatre semaines plus tard : 1 940 $ (−39 %), latence P95 tool calls −14 %. Action clé : migration du Gateway OpenClaw vers un Mac M4 Max 64 Go distant en launchd ; le MacBook Air 16 Go local n'héberge plus le gateway 7×24 — mémoire unifiée préservée pour montage et ComfyUI. Données client : voie dollar uniquement ; batches agents anonymisés. »
L'étude confirme la thèse : ce n'est pas le modèle le plus intelligent, mais le plus routé qui fait avancer l'IA en production. Investisseurs, développeurs et chercheurs lisent désormais le volume de tokens comme baromètre commercial — plus comme simple métrique technique. Studio parisien, six postes, pipelines vidéo IA + développement agent — résultats reproductibles pour toute équipe >2 M tokens/jour.
Métriques étendues : succès tool calls 91 % → 94 % ; tickets Opus 340 → 128/mois (−62 % grâce au triage) ; charge CPU gateway distant stable 38–45 % vs throttling thermique sur Air local. Aucune régression en revue créative aveugle (n=50 prompts, même grille qu'étape 5).
9. Chiffres citables et checklist d'acceptation
① Volume hebdo global : 28,9 billions (+7,4 %). ② Modèles chinois : 9,223 billions (+19,89 %). ③ Série DeepSeek : 5,74 billions. ④ Anthropic : ~12 % tokens / ~46 % revenus USD. ⑤ Croissance annuelle : ~12× (2,4 T→28,9 T). ⑥ Part code : 11 %→50 %+ (a16z). ⑦ Semaine juin plateforme : 33 T+.
Checklist : capture Top 10 archivée □ | double voie tokens/dollars □ | trois voies Mac documentées □ | plafond voie dollars □ | comparaison 50 prompts □ | Gateway Mac distant launchd □ | modèles gratuits sans données sensibles □
Windows, Linux ou serveurs cloud peuvent aussi brancher OpenRouter — mais pour des workflows où Xcode, Final Cut, ComfyUI, OpenClaw en launchd et validation MLX Metal coexistent, macOS reste l'environnement le plus fluide. Si vous souhaitez isoler physiquement « inférence MLX locale » et « modèles expérimentaux du classement + API agents à l'échelle du billion », sans saturer les 16 Go de mémoire unifiée : un nœud Mac distant MACGPU peut héberger OpenClaw et le routage gris ; la machine locale conserve Cursor et la voie dollars — location de compute contre facture prévisible et thermique maîtrisée.