2026 OPENROUTER
BILLING_
BEATS_
BENCHMARKS.
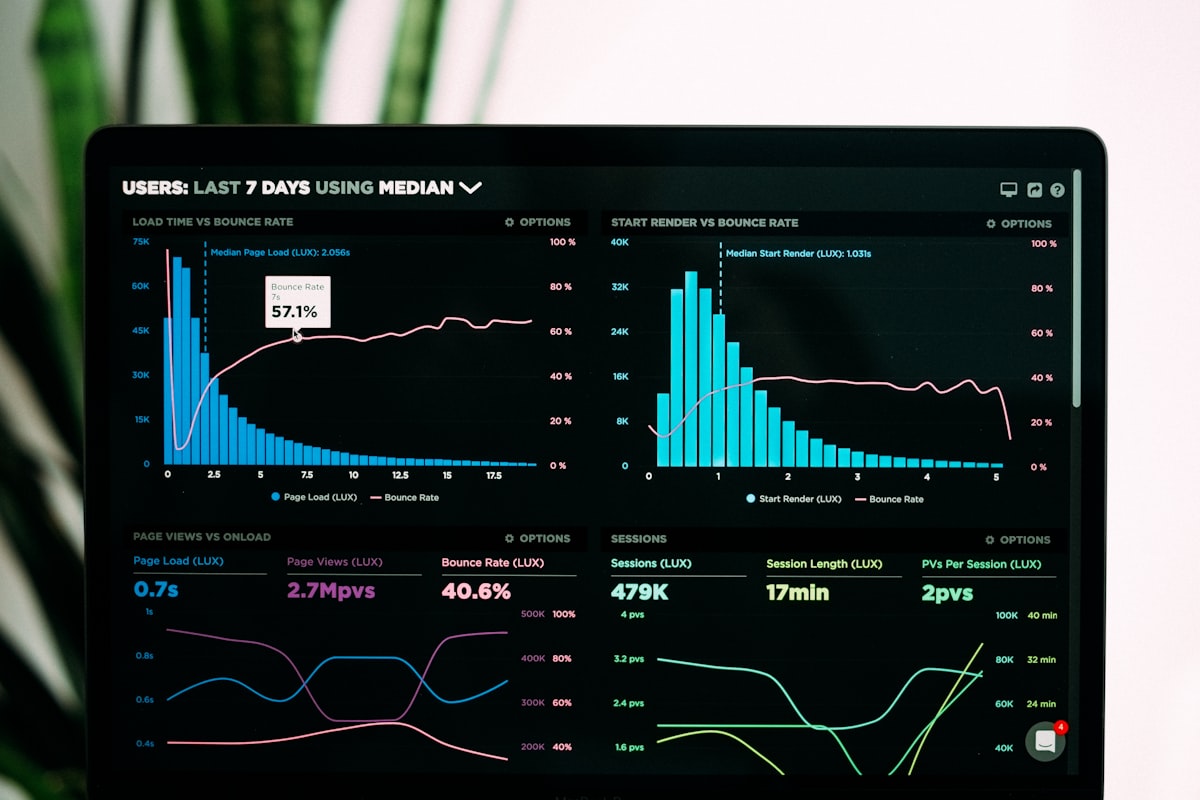
MMLU leaders rotate every quarter, but OpenRouter settled 28.9 trillion tokens in the week of May 18–24, 2026—and that ledger does not lie. DeepSeek-V4-Flash topped the chart at 3.43T; Chinese models logged 9.22T weekly volume, outpacing the United States for the fourth straight week. Pain point: developers still pick models from vendor benchmarks while their bills vote for cheap, high-throughput routes. Conclusion: weekly token volume is the thermometer of AI commercialization; Anthropic holds roughly 12% of traffic yet captures about 46% of dollar revenue, exposing the inversion between evaluation leaderboards and market leaderboards. Roadmap: data source, global totals, Top 10, vendor dual truth, a16z counterintuitive finding, five routing steps, case study, Mac three-tier split.
1. Pain Points: Why Billing Beats Benchmarks
1) Benchmarks can be gamed; routed tokens cannot. Leaderboard scores reflect tuned prompts on fixed eval sets. OpenRouter weekly throughput reflects production load at scale—retries, tool-call loops, context truncation, and provider failover included. When a trillion tokens flow through a model in seven days, someone is paying (or consciously choosing free tier risk) because latency, price, and agent stability work in their environment.
2) "Strongest" is not the same as "most used." Claude Opus remains the reference for hard reasoning and compliance reviews, but its weekly token count can be a fraction of DeepSeek Flash. Enterprises pay premiums for quality floors; high-frequency agent fleets pay for throughput. Routing tables that default everything to Sonnet-class models are optimizing for prestige, not for the workload distribution the platform already shows.
3) The US–China volume map has flipped. In early 2025, Chinese models accounted for under 2% of OpenRouter weekly traffic. By May 2026, China-origin models exceed 45% of platform volume. Mac teams whose fallback chains still list only GPT and Claude as primaries are structurally behind on unit economics—even though OpenRouter makes model switching a configuration change, not a migration project.
4) Programming is now the dominant single use case. The OpenRouter × a16z 2025 AI Usage Report, built on roughly 100 trillion tokens of anonymized metadata, shows programming tasks rising from about 11% of token share at the start of 2025 to more than 50% by year end. Model selection must be scenario-split: IDE assist, batch agents, multimodal docs, and security audit cannot share one "best model" label without blowing the budget or sacrificing tool-call reliability.
The operational mistake is treating weekly rankings as entertainment. They are a live price discovery mechanism. Every point of share shift on V4-Flash or Hy3 preview is a market signal that your Cursor default, OpenClaw gateway, and Dollar-track escalation policy should absorb within days—not next quarter.
2. Data Source and Methodology
Core figures in this article come from the public openrouter.ai/rankings leaderboard. The measurement window is a rolling seven-day token throughput count, including both input and output tokens across all routed requests on the platform. OpenRouter aggregates 300+ models from 60+ providers, processes on the order of 100 trillion tokens per month, and serves more than 8 million users—making its weekly chart one of the few neutral, multi-vendor, multi-region samples of real AI inference demand.
Primary snapshot: May 18–24, 2026. By early June, third-party trackers already placed platform weekly totals above 33T; directionally consistent with late-May momentum. Cross-references include National Business Daily coverage (2026-05-25), the OpenRouter × a16z usage report, and June industry digests from Digital Applied and similar outlets. Rankings are volatile: Kimi K2.6 held sixth place the prior week and dropped out of the Top 10 in this window—evidence that routing policies need weekly diffs, not quarterly defaults.
Important caveat: token volume measures throughput, not outcome quality. A high-rank model may reflect aggressive free tiers (Owl Alpha) or extreme price compression (V4-Flash). Dollar revenue charts on the same platform tell a different story—covered in Section 5 and in our dual-track leaderboard routing article.
3. Global Weekly Totals: 28.9 Trillion Tokens, Five Weeks of Growth
| Metric | Value | WoW | Interpretation |
|---|---|---|---|
| Global weekly volume | 28.9T tokens | +7.4% | Fifth consecutive weekly increase; inference at scale |
| China-model weekly volume | 9.223T | +19.89% | Growth above global mean; share expansion |
| US-model weekly volume | 4.93T | +16.27% | Still growing, but losing share |
| China vs US | China > US | 4th straight week | China models lead global weekly throughput |
| Year-over-year scale | ~2.4T → 28.9T | ~12× | Weekly platform volume roughly twelvefold vs one year prior |
Scale check: 28.9 trillion tokens in one week exceeds the demo traffic any single vendor showcases at a launch event. This is commercial deployment volume—IDE plugins, agent gateways, batch summarization, RAG pipelines, and internal tools running concurrently. The +7.4% global WoW figure is not a hype spike from one free preview; it is the fifth week in a row of platform-level growth, which is what you expect when AI shifts from chat experiments to always-on infrastructure.
China-model growth at +19.89% versus US-model +16.27% explains why five of ten individual model slots in the weekly Top 10 are China-team releases. The US still grows in absolute terms—Anthropic and Google routes are not collapsing—but the marginal token is increasingly Chinese open-weights or Chinese API pricing. Mac developers should read that as a routing mandate, not a geopolitical sidebar: your $/M and P95 tool-call latency already depend on models you may not have in yesterday's fallback list.
4. Top 10 Models by Weekly Token Volume (May 18–24)
| Rank | Model | Vendor | Weekly tokens | WoW | Role |
|---|---|---|---|---|---|
| 1 | DeepSeek-V4-Flash | DeepSeek (China) | 3.43T | +66% | Agent workflows; ultra-low $/M |
| 2 | Tencent Hy3 Preview | Tencent (China) | 3.07T | +16% | Open MoE; sustained post-preview demand |
| 3 | Claude Sonnet 4.6 | Anthropic (US) | 1.35T | — | 1M context; enterprise coding workhorse |
| 4 | DeepSeek-V3.2 | DeepSeek (China) | 1.31T | — | Prior-gen value tier; long-tail workloads |
| 5 | Owl Alpha | OpenRouter | 1.15T | +29% | Free agent-specialized; 1M context |
| 6 | Gemini 3 Flash Preview | Google (US) | 1.06T | — | Multimodal; academic and medical docs |
| 7 | DeepSeek-V4-Pro | DeepSeek (China) | 1.00T | — | Matrix flagship; series total ~5.74T |
| 8 | MiniMax M2.7 | MiniMax (China) | 806B | — | Long-context price/performance |
| 9 | Grok 4.1 Fast | xAI (US) | 721B | — | 2M context; legal and research |
| 10 | Step 3.5 Flash | StepFun (China) | 673B | — | Fast, low-cost batch processing |
DeepSeek multi-model matrix dominance: V4-Flash, V4-Pro, and V3.2 all placed in the Top 10 simultaneously. Combined series volume reached approximately 5.74T for the week (+25.9% WoW at the vendor level), exceeding Anthropic and Google on token throughput for the second consecutive week. That is not one lucky SKU—it is a portfolio strategy: Flash for agent loops, Pro for harder reasoning, V3.2 for price-sensitive legacy routes.
Hy3 preview at 3.07T proves that traffic can persist after promotional pricing ends—important for teams debating whether to anchor on limited-time free tiers. Owl Alpha at 1.15T (+29%) shows how a zero-dollar route can absorb prototyping and internal automation volume, with the obvious security caveat that stealth or free models must never see customer credentials. Sonnet 4.6 at third place confirms the Dollar-adjacent daily driver role: not the volume king, but still essential for teams that need Anthropic tool schemas and policy familiarity on mid-tier spend.
Notable absence: Kimi K2.6 fell out of the Top 10 after ranking sixth the prior week. Weekly rankings punish delay—if your openclaw.json still lists K2.6 as primary because of a March blog post, you are routing against the current market, not with it.
5. Vendor Landscape: Token Volume vs Dollar Revenue
| Lane | Representatives | Token profile | Revenue profile | Typical workloads |
|---|---|---|---|---|
| High value, low volume | Claude Opus 4.6/4.7 | Share declining (~12%) | ~46% of platform dollars | Enterprise reasoning, compliance, security audit |
| Mid ARPU, steady growth | Gemini 3 Flash | Stable Top 10 presence | Moderate revenue per token | Multimodal docs, academic pipelines |
| Ultra-low price, high volume | DeepSeek / Hy3 / MiniMax | Combined 45%+ of tokens | Revenue share far below token share | Agents, programming, batch jobs |
The Anthropic premium paradox: enterprise buyers still pay flagship prices for Claude—press reports have cited Opus-class monthly revenue on the order of $25 million at peak routing share—but traffic leadership has shifted to low-cost open matrices. Anthropic is not "losing"; the market is splitting into a Token track (volume, $/M, agent throughput) and a Dollar track (liability, reasoning depth, procurement approval). Mac teams need both tracks explicitly configured: daily agents and IDE assist on V4-Flash or Hy3; architecture review and security gates on Opus with a hard budget cap.
Token share and revenue share diverge because ARPU spans orders of magnitude. V4-Flash public OpenRouter pricing sits near $0.10–0.14/M input depending on provider route; Opus-class output pricing can approach $25/M. A single escalated refactor session on Opus can cost more than a week of Flash-backed agent traffic. The weekly leaderboard makes that imbalance visible: Chinese open models win on tokens, Anthropic wins on dollars. Neither chart alone is sufficient for routing—see the dual-track playbook linked above for Cursor vs OpenClaw chart linkage and Provider-layer decisions.
Investor and operator implication: OpenRouter's own valuation narrative has referenced premium revenue multiples (press reports near 26× price-to-sales at certain funding stages) precisely because Dollar-track concentration on Anthropic coexists with explosive Token-track growth on Chinese models. Developers feel this as a personal finance problem; finance teams feel it as margin structure. Same platform, two optima.
6. Counterintuitive Finding: Benchmark Scores Invert Against Market Share
The OpenRouter × a16z 2025 AI Usage Report analyzed on the order of 100 trillion tokens of anonymized usage metadata. Its central finding is uncomfortable for benchmark-centric procurement: model benchmark scores and actual market share are nearly inversely related. Models that dominate MMLU, GPQA, or single-shot reasoning leaderboards often sit far below Flash-tier routes on weekly token charts.
The mechanism is straightforward. Production developers optimize for inference cost, API latency, tool-call stability, and context economics—not marginal gains on static eval items. Agent workflows need predictable throughput across hundreds of steps; a model that scores 2% higher on a coding benchmark but costs 20× per million output tokens gets replaced in Cursor within a sprint. Programming crossing 50% of token share amplifies the effect: SWE-bench leaders priced like premium flagships lose to V4-Flash when an IDE fires millions of tokens per developer per week.
Secondary factors reinforce the inversion. Long-context pricing multiplies quickly when teams dump whole repositories into prompts without compaction. Free tiers (Owl Alpha) reset mental price anchors. MoE architectures deliver active-parameter efficiency that dense flagship models cannot match at the same $/M. Multimodal needs pull volume toward Gemini Flash and Opus vision routes even when text-only leaderboard champions look "smarter" on paper.
Conclusion for practitioners: the honest leaderboard is the billing export and the OpenRouter weekly chart—not the vendor press release. If your model policy cites benchmark rank but never cites token share or $/M, it is stale by design. Re-read rankings every Monday; treat a 30%+ WoW move as a routing ticket, not a tweet.
7. Five Steps: Encode the Weekly Chart in Your Mac Workflow
Step 1 — Monday rankings archive and Top 10 diff
Screenshot openrouter.ai/rankings every Monday. Record rank changes and any model with WoW growth above 30%. New Top 10 entrants—Owl Alpha in this cycle—often predict the next gray-pool or agent-primary candidate. File diffs next to your openclaw.json or Cursor provider config the same day.
Step 2 — Split routes by scenario; ban one global default
Agent and batch processing → DeepSeek-V4-Flash primary. Enterprise complex reasoning → Claude Opus on Dollar track only. Multimodal document ingestion → Gemini 3 Flash. IDE (Cursor) and gateway (OpenClaw) get different primaries because the Programming Collections chart and Top Models chart diverge—documented in our ten-dimension weekly snapshot article. A single default across all surfaces is how teams end up paying Sonnet prices for summarization that Flash handles at a tenth of the cost.
Step 3 — Label Mac three tiers: local MLX / OpenRouter API / remote Mac
Tier A — local MLX: steady-state 7B–32B quantized models for drafts, offline snippets, and privacy-sensitive microtasks on Apple Silicon unified memory. Tier B — OpenRouter API: 1M-context experiments, model churn, and overflow when local KV cannot fit. Tier C — remote Mac node: 7×24 OpenClaw gateway, gray routing, and regression hosts—launchd-managed, not a sleeping MacBook Air cooking its keyboard.
Step 4 — Dollar-track monthly budget cap with automatic downgrade
Reserve Opus and premium GPT routes for architecture review, security audit, and explicit escalations. Set a hard monthly Dollar-track ceiling; if spend exceeds budget by 15%, auto-downgrade the following week to V4-Flash or Hy3 for all non-incident traffic. Token-track growth on the leaderboard is useless if Dollar-track drift silently consumes the savings.
Step 5 — Weekly 50-prompt acceptance harness
Run the same fifty prompts through local MLX, OpenRouter primary, and remote Mac secondary. Log P95 latency, estimated $/run, and tool-call success rate. Promote or demote models on harness diffs—not on social media release notes or vendor benchmark PDFs. The harness is your private benchmark; the platform weekly chart is the public one. Align both.
8. Case Study: Six-Person Mac Team Cuts Monthly Bill 39% Using the Weekly Chart
"The team defaulted Claude Sonnet across IDE, agents, and docs—about $3,200/month on OpenRouter. After mapping the May 18–24 weekly chart: 62% of tokens moved to DeepSeek-V4-Flash for agents and Cursor; 18% to Hy3 preview gray pool; 12% to Gemini 3 Flash for multimodal docs; only 8% remained on Opus for security audit. Four weeks later the bill was $1,940 (-39%), with P95 tool-call latency down 14%. The critical move was migrating OpenClaw Gateway to a remote Mac M4 Max 64GB; the 16GB Air stopped running 7×24 and kept unified memory for Final Cut and ComfyUI."
The case validates the article thesis: what gets called most drives AI landing cost, not what scores highest in isolation. Investors use weekly platform growth—28.9T globally, ~12× year-over-year—to judge commercialization velocity; operators use the same data to pick models; researchers use it to track regional and scenario shifts. Token volume graduated from a technical curiosity to a business weather vane.
Implementation details matter. The team did not blindly switch models—they mapped task classes first: high-frequency tool loops to Flash, multimodal customer PDFs to Gemini, compliance review to Opus with ticket IDs required for each escalation. They blocked Owl from repositories containing customer data. They set compaction rules before sending large monorepo slices to 1M context. They separated Provider selection (official vs aggregator routes) per model family to shave another few percent off $/M. Gray pool traffic stayed under 10% with automatic rollback when tool-call error rate rose two points week-over-week.
Mac-specific lesson: the savings were not only from cheaper models. Moving the always-on gateway off the laptop avoided swap thrash and thermal throttling that had been inflating latency and retry rates—retry storms show up as token volume and cost. Remote Mac with launchd gave predictable P95; local machine returned to MLX sidecar validation and creative tooling. That split is harder to replicate on a Windows/Linux box without an equivalent unified-memory local inference path.
9. Citable Figures and Acceptance Checklist
① Global weekly volume: 28.9T tokens (+7.4% WoW). ② China-model weekly volume: 9.223T (+19.89%). ③ US-model weekly volume: 4.93T (+16.27%). ④ DeepSeek series combined: 5.74T. ⑤ Anthropic: ~12% tokens / ~46% dollar revenue. ⑥ Year-over-year weekly scale: ~12× (2.4T → 28.9T). ⑦ Programming task token share: 11% → 50%+ per OpenRouter × a16z. ⑧ Case study bill change: -39% after four weeks.
Acceptance checklist: Weekly Top 10 screenshot archived □ | Token/Dollar dual tracks split □ | Three-tier Mac split documented □ | Dollar-track budget cap configured □ | 50-prompt weekly harness running □ | Remote Mac Gateway always-on □ | Free models blocked for sensitive data □
Windows and Linux clients can call OpenRouter equally well, but macOS still wins on integrated workflows: Xcode and Final Cut beside a launchd-hosted OpenClaw gateway, Metal-backed MLX sidecars for local validation, and ComfyUI batches without WSL GPU passthrough fights. If you want steady local inference isolated from weekly-chart experimental models and trillion-token agent APIs—so a 16GB notebook is not held hostage by gateway KV growth—MACGPU remote Mac nodes can host OpenClaw and gray routes while the laptop keeps Cursor review and Dollar-track escalations. Renting compute buys predictable monthly cost and thermals versus running a 7×24 gateway on hardware meant for editing sessions.